近日,国产a片
智能运维实验室的论文《Efficient and Accurate Anomaly Detection in HPC Systems via Coarse-Grained Clustering and Fine-Grained Model Sharing》被高性能计算领域的顶级国际会议——International Conference for High Performance Computing, Networking, Storage, and Analysis(SC)2025录用(CCF推荐A类会议)。该会议将于2025年11月16日至11月21日在美国圣路易斯举行。以下是论文简介:
论文标题:Effective Node-Level Anomaly Detection in HPC Systems via Coarse-Grained Clustering and Fine-Grained Model Sharing
作者:夏思博,孙永谦*,潘希杰,袁远*,张圣林,胡绍宇,陶磊,李宇奇,冯景华
作者单位:国产a片
、中国人民解放军国防科技大学、国家超级计算天津中心
Part.1 摘要
高性能计算(High-Performance Computing, HPC)系统在科学进步和工程突破中发挥着关键作用,其性能下降或系统故障会对相关研究产生严重影响。本文介绍了 NodeSentry,一个专为大规模 HPC 系统计算结点设计的新型无监督异常检测框架。NodeSentry 采用粗粒度聚类与细粒度模型共享相结合的方法,有效应对了现代 HPC 部署所面临的巨大结点规模、频繁作业切换及复杂模式特征等挑战。
在两个真实的 HPC 系统数据集上的评估表明,NodeSentry 具备优越的性能,其 F1 分数超过 0.876,相较于现有最佳基线方法平均提升了 0.560,同时将训练开销平均降低了 45.69%。此外,为了推动研究结果的可复现性,并为更广泛的研究做出贡献,我们开源了 NodeSentry 的代码库,并实现了一个专为 HPC 系统设计的聚类调整与异常标注工具。
Part.2 背景与挑战
HPC系统通常由大量计算结点组成,这些结点通过高速、低延迟网络连接,形成集群或超级计算机。每个结点配备多个处理器核心和大量内存容量,众多结点通常会联合起来处理一个大规模计算任务。HPC系统的复杂架构和高度动态的作业调度显著增加了系统故障的可能性。因此,实时识别性能异常是至关重要的。
然而,现有的异常检测方法存在一些局限性。一些方法假设多维时间序列(MTS)具有稳定的模式和强周期性,这在HPC系统中并不总是成立。HPC系统的MTS具有以下独特特征:
1. 海量结点与高维指标的开销壁垒:为单结点训练独立模型需处理数千维指标(如本研究场景含3,014维),导致计算与存储成本随结点规模指数级增长;
2. 动态作业转换和作业模式相关性:HPC中作业通常是复杂的,需要跨多个结点进行分布式协作执行,而从单个结点的角度来看,作业在不断切换;
3. 作业内子模式演化的建模盲区:即使不同作业的MTS可能表现出相似的模式,但单个作业内的细粒度模式(子模式)并非静态的,现有模型难以捕捉同一作业内细粒度的动态时序变异。
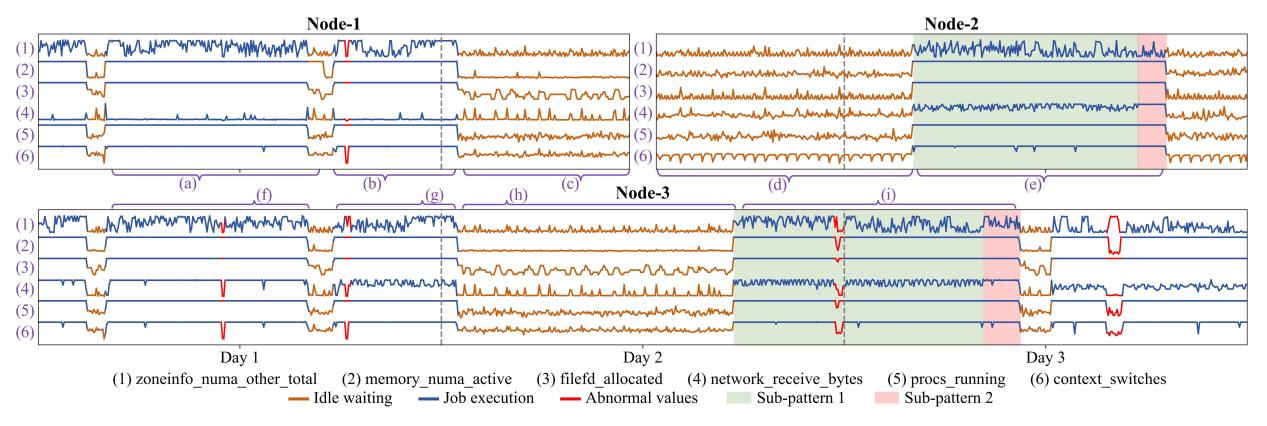
图1:三个结点的六个指标示例,其中两个结点持续1.5天,一个结点持续3天。相似的模式对:(a)–(f), (c)–(h), and (e)–(i);不同的模式对:(b)–(g) and (d)–(h)。
Part.3 核心方法与系统架构
NodeSentry 的创新思路正是源于对这些特征观察与分析:与其固守“结点中心”的视角,不如将分析的基本单元转向驱动结点行为的核心——作业。 通过利用HPC作业管理系统(如Slurm)提供的作业起止时间信息,我们可以将结点上连续的时间序列精确地切分成代表不同作业执行的时间片段。NodeSentry提出“作业驱动”的创新范式,通过三级流程解决上述挑战:
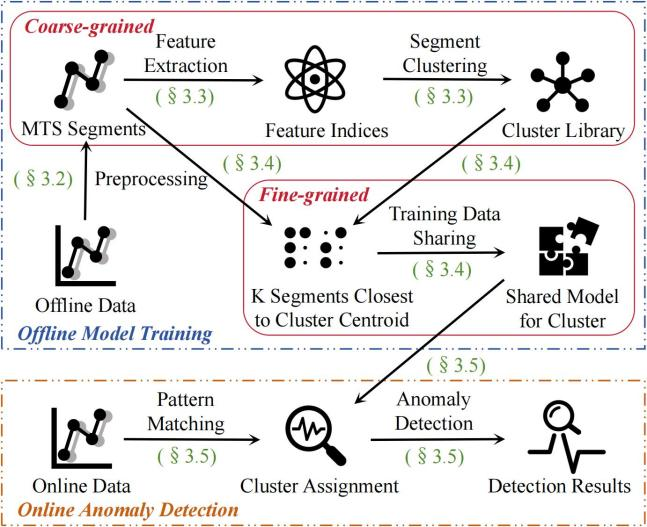
图2:NodeSentry的整体框架。
1. 作业片段化与粗粒度聚类
基于Slurm作业调度信息,将结点原始MTS按作业起止时间精准切割为独立片段,消除跨作业模式干扰。针对片段长度不一、维度高等难题,设计多尺度特征提取方案:融合统计特征、时域特征、频域特征等134维指标,将变长片段压缩为定长特征向量。通过层次聚类实现粗粒度模式归类,相似作业被聚合至同一聚类簇,使模型训练量锐减。
2. 细粒度专家建模与动态共享
为克服同一聚类簇内子模式差异,采用“Transformer+MoE”自适应架构为每个聚类簇训练单一共享模型,Transformer编码器捕获片段内长程时序依赖,混合专家层替代传统全连接层,由多组专家网络组成。门控机制动态分配输入数据至最相关的1-3个专家,使不同专家专注学习特定子模式。通过加权重建误差 联合优化,实现“一个模型适配多子模式”。
3. 在线检测与增量进化
在线异常检测阶段,NodeSentry利用预处理后的MTS特征与聚类库中的模式进行匹配,然后使用相应的共享模型进行异常检测。通过计算输入数据和重构数据之间的重构误差,可以确定输入MTS是否接近正常行为,从而得出异常分数。如果异常分数超过设定的动态阈值,则认为该数据点存在异常。针对未知模式,启动增量聚类与模型微调,避免全局重训练。
Part.4 实验验证与部署成效
为了验证NodeSentry的性能,实验结果表明NodeSentry在F1分数上达到了0.876和0.891,相较于现有的最佳基线方法分别提高了0.562和0.558,同时在训练开销上相较其他深度学习方法分别减少了77.93%和13.45%。这些结果表明,NodeSentry在异常检测的准确性和效率方面都具有显著的优势。为了验证NodeSentry中各个关键组件的有效性。实验结果表明每个组件都对NodeSentry的性能提升做出了重要贡献。

表1:不同方法的异常检测性能
在部署方面,NodeSentry在实际的HPC生产环境中进行了部署和测试。在一个月的连续评估期间,NodeSentry展示了高效的运行性能,每个小时的监控周期的模式匹配平均完成时间为5.11秒,每个采样点的实时检测延迟为36毫秒。在识别性能异常方面,NodeSentry的精确度和召回率分别为0.857和0.923,这表明NodeSentry在实际应用中具有优秀的异常检测能力。
Part.5 研究意义与展望
NodeSentry为大规模 HPC 系统的结点级异常检测提供了一种高效且准确的无监督解决方案,其主要贡献在于:
1. 范式转变:NodeSentry分析单元从“计算结点”转向“作业”,充分利用了 HPC 系统的作业调度信息,为处理作业动态性和模式复杂性奠定了基础。
2. 两级处理架构:结合 “粗粒度聚类” 和 “细粒度模型共享”,有效解决了海量作业片段分类与同一作业内子模式变化的双重挑战。MoE 机制的引入是实现细粒度、自适应模型共享的关键。
3. 显著性能提升:在真实数据集上验证了其卓越性能,证明了该框架的有效性和高效性。
4. 促进后续研究发展:开源代码和专用工具的发布,极大地方便了学术研究与工业界复现、应用及进一步创新。
展望未来,NodeSentry 的核心思想——“以任务/作业为中心进行分析”和“粗分类+细粒度专家建模”——具有推广到其他复杂分布式系统(如GPU集群)的潜力。随着异构计算和AI工作负载的普及,进一步优化模型以适应更复杂的环境和新型异常模式,将是重要的研究方向。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350